
Hello aspiring ethical hackers. In Part-1 of website footprinting, you learnt how to gather information about a website by using methods like grabbing banners, directory scanning and spidering. In this Part-2, you will learn about some more techniques for footprinting websites.
4. Website mirroring
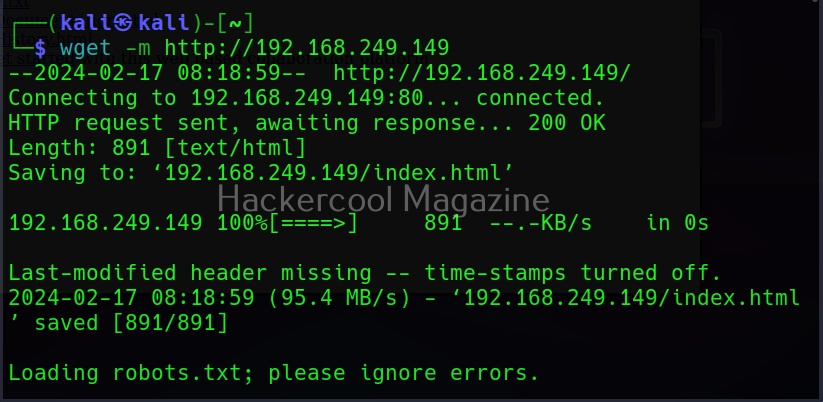
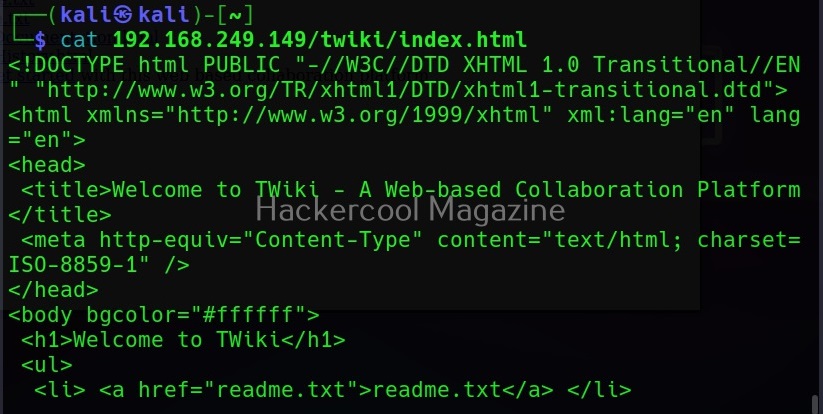
Either you are directory scanning or spidering, you are sending a lot of requests to the website (especially if the website is very large) which may raise suspicions or on the target side or you will be blocked. What if there was an effective workaround for this. Actually, there is. Instead of sending requests to the target website, we can download the entire website to your local device. This is known as website mirroring. For example, let’s mirror a website using wget as shown below.



5. Footprinting websites using online services
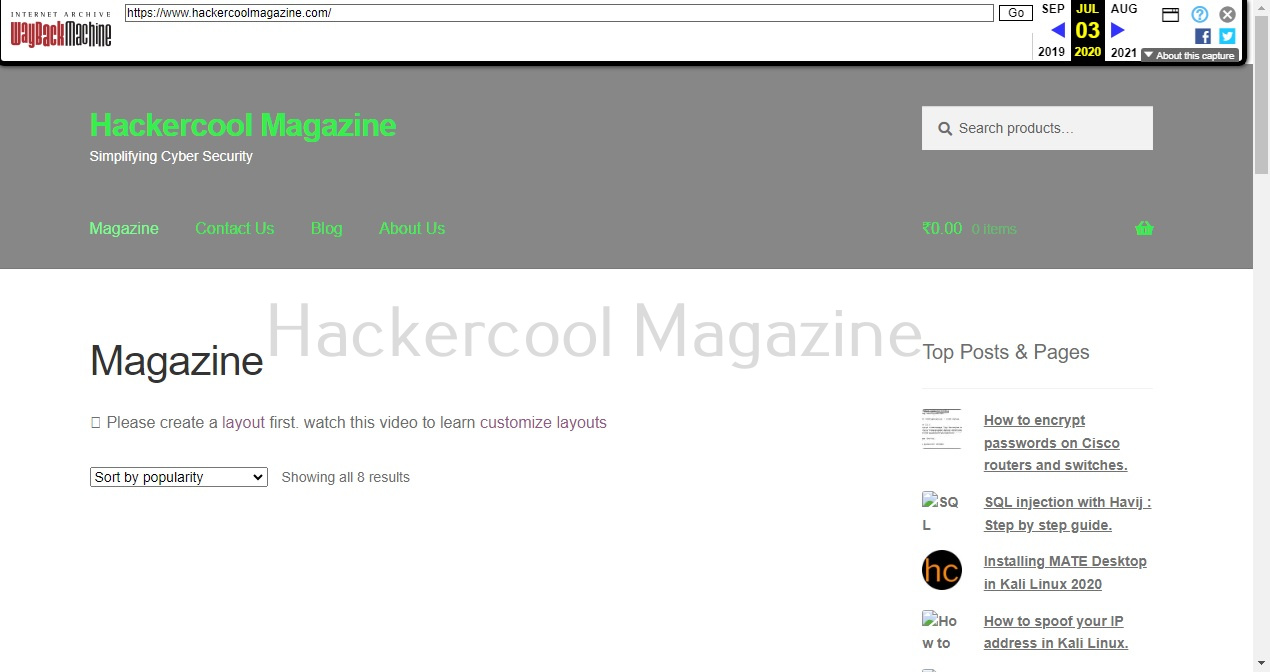
A website is constantly updated. The information that is displayed on the website last year may not be there today. What if there was a way to go back in time to view the past versions of a website for gathering information. Actually, there is a way for this. By using the website archive.org. Archive.org collects the snapshot of the website at different points in time from the time the website existed and stores it. So, you can go there and view how the website looked 10 years back ago or three years ago. For example, this is how our website looked way back in 2018.
Better, you can constantly monitor the updates being made to the websites using a website known as website watcher.
Website watcher automatically checks webpages for any updates and changes.
Follow Us