
Hello, aspiring Ethical Hackers. In our previous article, you have learnt what is Foot printing, why it is important and how many types of Foot printing techniques are there. Website Footprinting is one type of Foot printing.
What is Website Footprinting?
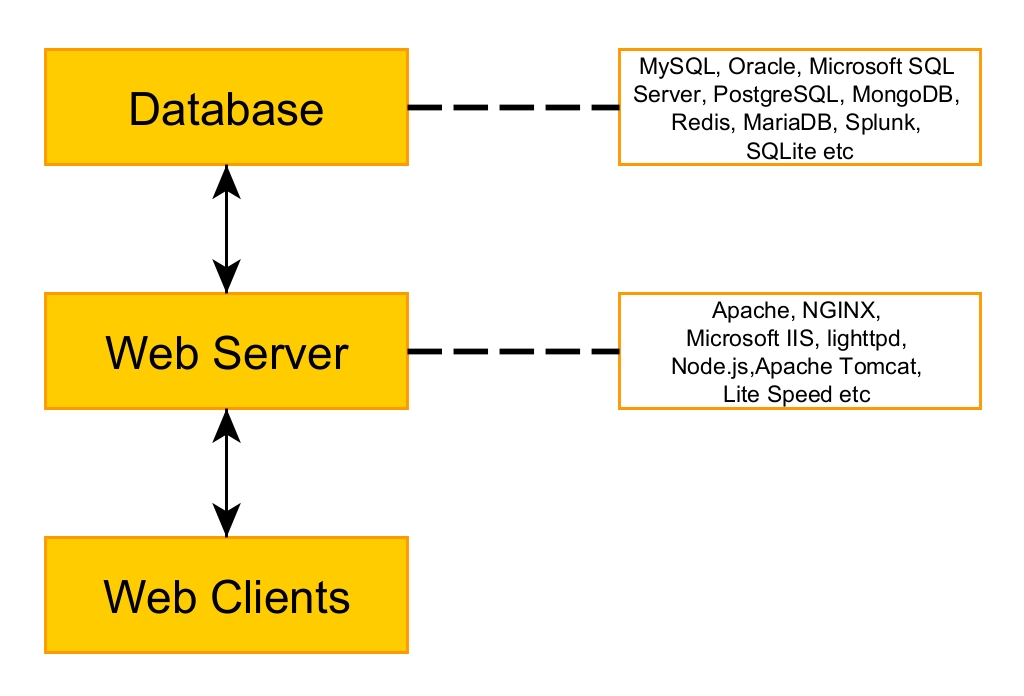
Website Footprinting is the process of analyzing target’s website to gather as much information as possible that may prove helpful in penetration testing or hack depending on which Hat you wear.
What information does Website Footprinting reveal?
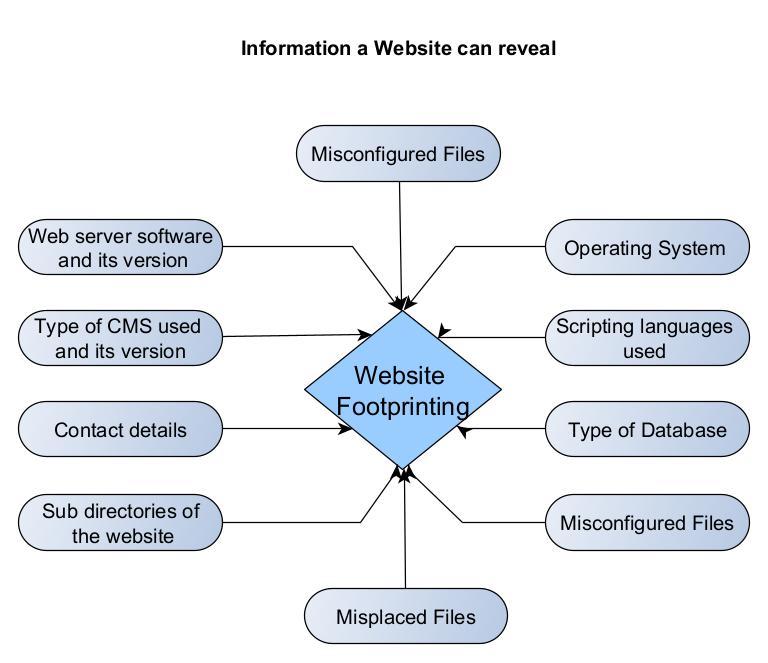
Website Footprinting reveals the following information.
- Webserver software and its version.
- Types of CMS being used and its version.
- Contact details.
- Sub directories of the website.
- Operating System of the target hosting the web server.
- Scripting languages used to code the website.
- Types of Database being used by the target website.
- Misconfigured files.
- Parameters used.
- Misplaced files.
How is Website Foot printing performed?
There are multiple methods to perform Website Footprinting. They are,
- Banner Grabbing
- Web Directory scanning
- Web spidering
- Website Mirroring
- Website Header Analysis.
1. Banner Grabbing
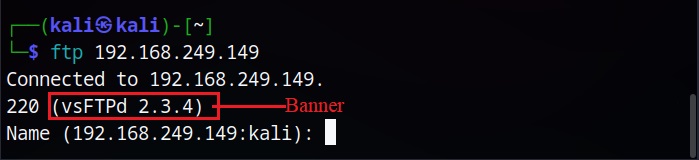
A Banner is a small piece of information that is displayed by services, programs or systems. This banner sometimes even consists of types of software used, its version and some other information related to the software and sometimes even the operating system behind it. Banner Grabbing is the method used to gain information about the services running on target system by grabbing this banner. Learn more about Banner Grabbing here.
2. Web Directory Scanning
Website directories are the folders present in website. Sometimes these directories contain sensitive files either placed there due to misconfiguration or by mistake. Not just that, there may be some hidden directories that cannot be accessed using the browser.
For example, earlier this year, the Brazilian retail arm of Swedish luxury vehicle manufacturer, Volvo, exposed sensitive files mistakenly on their website. These exposed files include their database’s authentication system (both MySQL and Redis), open ports, credentials and even website’s Laravel application key.
There are many tools to perform Website directory scanning. Let’s look at one tool that is installed by default in Kali Linux, dirb. Since I don’t want to spend my rest of my life in prison, I will not test this tool on any live website but on web services of Metasploitable 2.
The command to run “dirb” tool is very simple. It is as shown below.
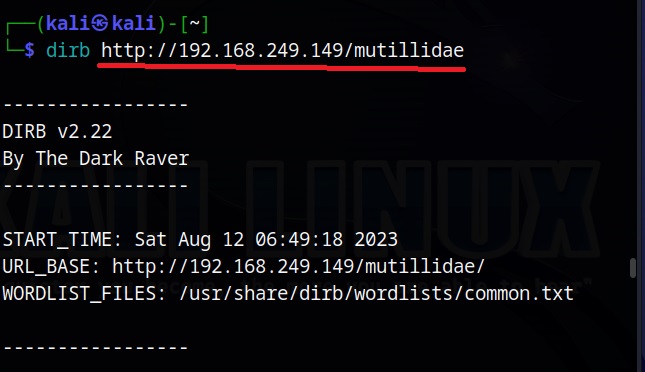
Just give it an URL and it starts scanning.
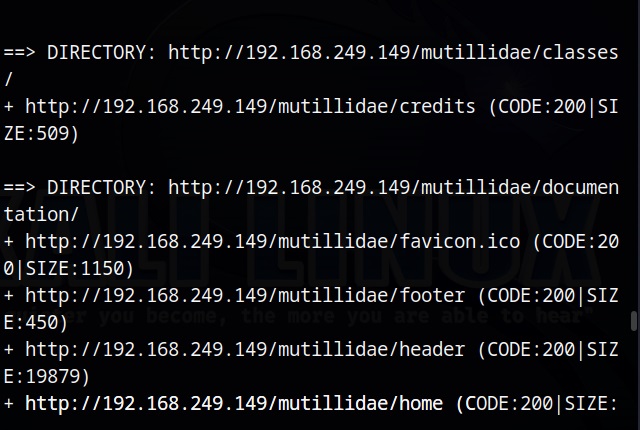
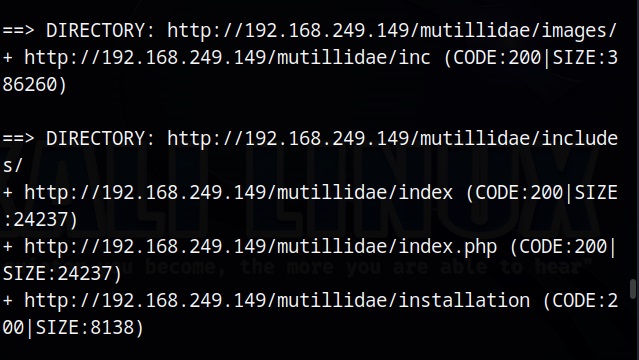
After the scan is finished, we can analyze the URLs one by one. Very soon, I found an interesting one.
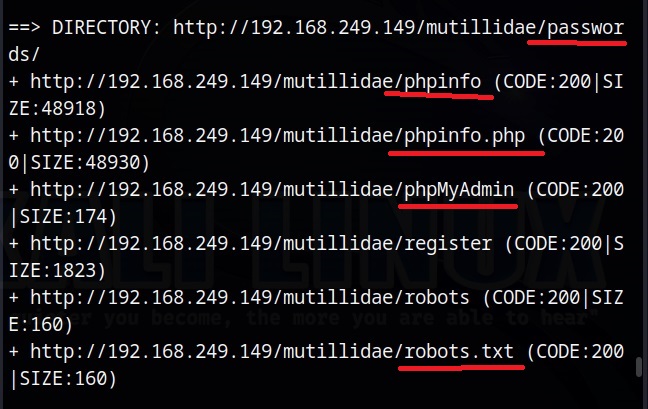
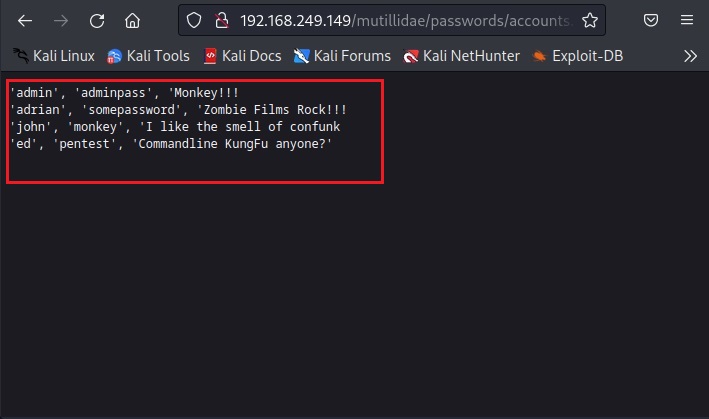
I first open the passwords directory and find a file named “accounts.txt” in it.
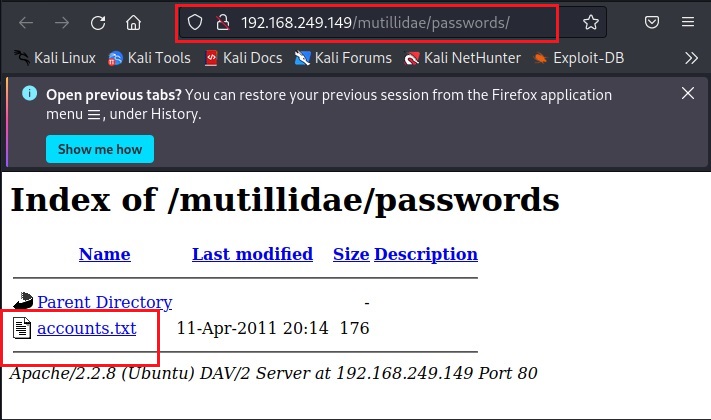
As I open it, I found some credentials. These appear to be users of Mutillidae web app.
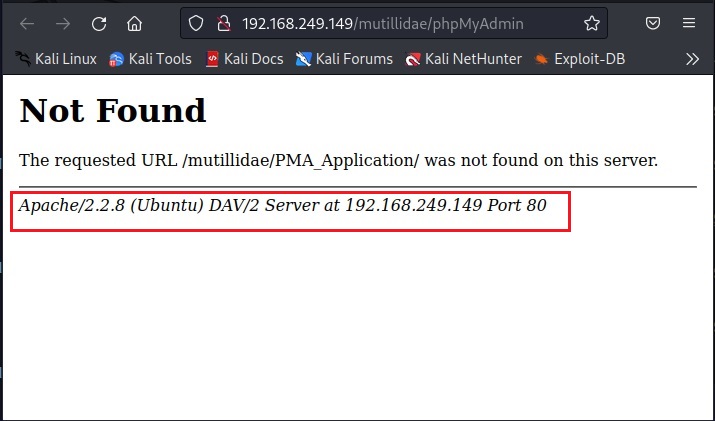
Then I open the phpMyAdmin page. phpMyAdmin is a database manager. Although I don’t get access to databases, I get some server and OS information of target.
Next interesting thing to check out is ‘robots.txt’ file. What is robots.txt? Robots.txt is a file specifically used to ask search engines not to index some files and paths. Any entry or path given in this robots.txt file is not indexed or crawled by a search engine spider. But here we can access it. Let’s see what it contains.
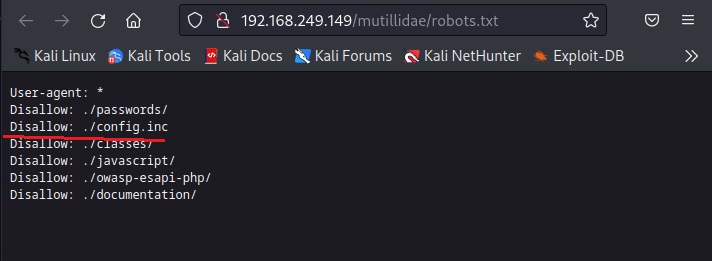
It has disallowed some six paths and files from indexing. Normally in these cases, any configuration file is a prized catch. So, let’s check out “config.inc” file.
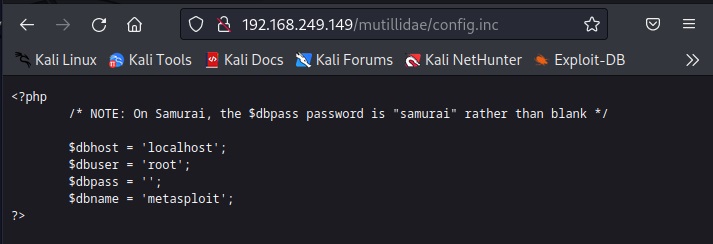
Once again, some credentials. But these appear to be belonging to a database.
3. Web Spidering or Crawling
Website crawling or spidering is a technique used to crawl through the links of a website to understand the structure of the website. This crawling sometimes reveal interesting links and pages on which Pen testers can focus on.
A crawler or spider works this way. When you give it an URL or webpage, it visits the URL and makes a list of all the hyperlinks present on that page. Then it visits the hyperlinks and repeat the process again recursively. In this way a website spider builds the structure of the entire website for hackers to get a better picture of their target.
There are many website spidering tools. For this tutorial, we will use the Web directory scanner module of Metasploit.
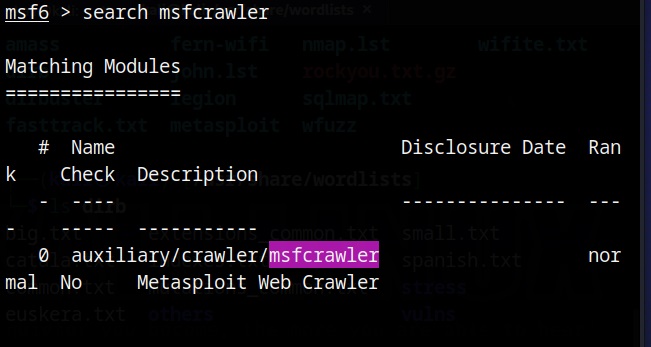
I will use it to scan mutillidae on Metasploitable 2.
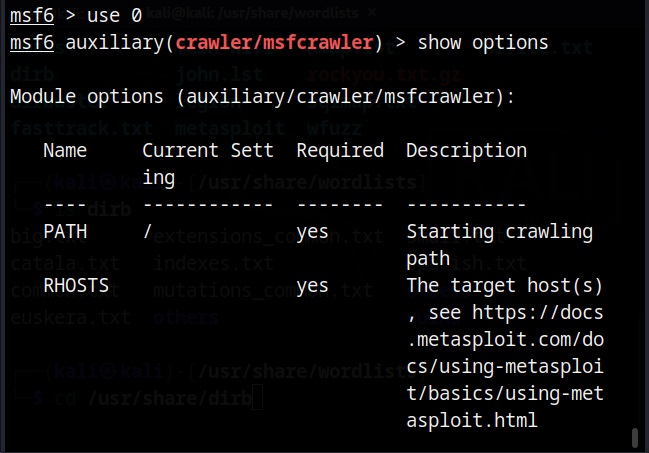
Set the target IP or URL and set the path.
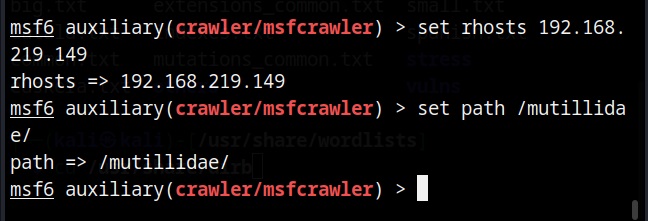
After all options are set, execute the module after loading some required modules to run, it starts crawling the target website.
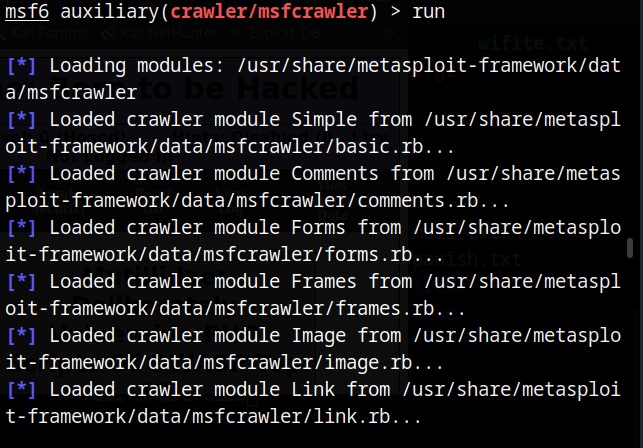
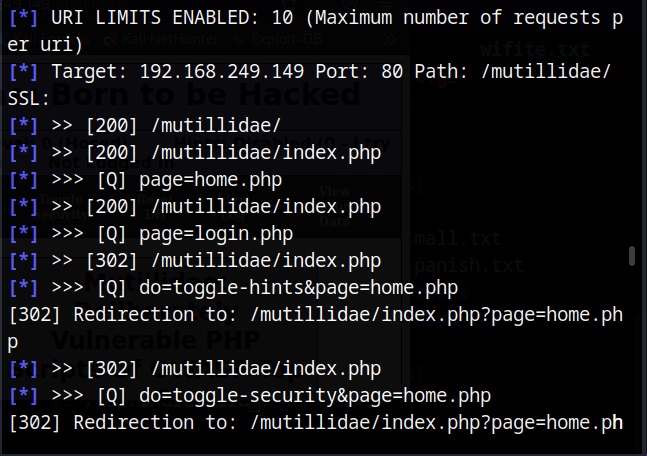
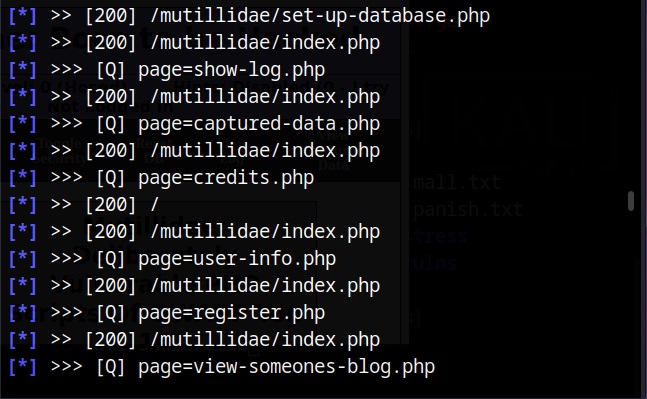
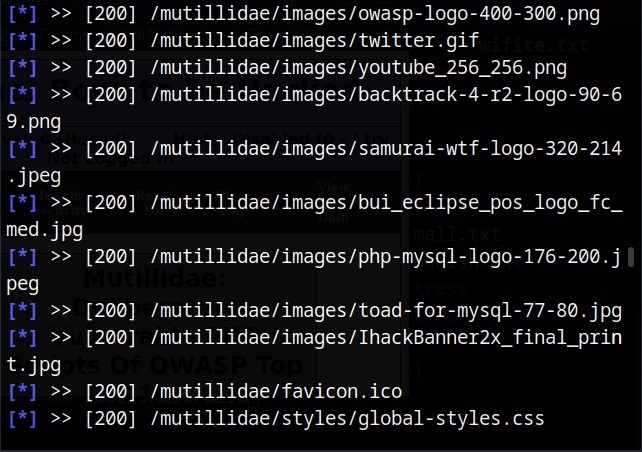
If the target website is too large, spidering can take a lot of time. That’s all in this blogpost. Readers will learn about website mirroring and how to gather information about target website using web services. Read Part 2 now.
Follow Us