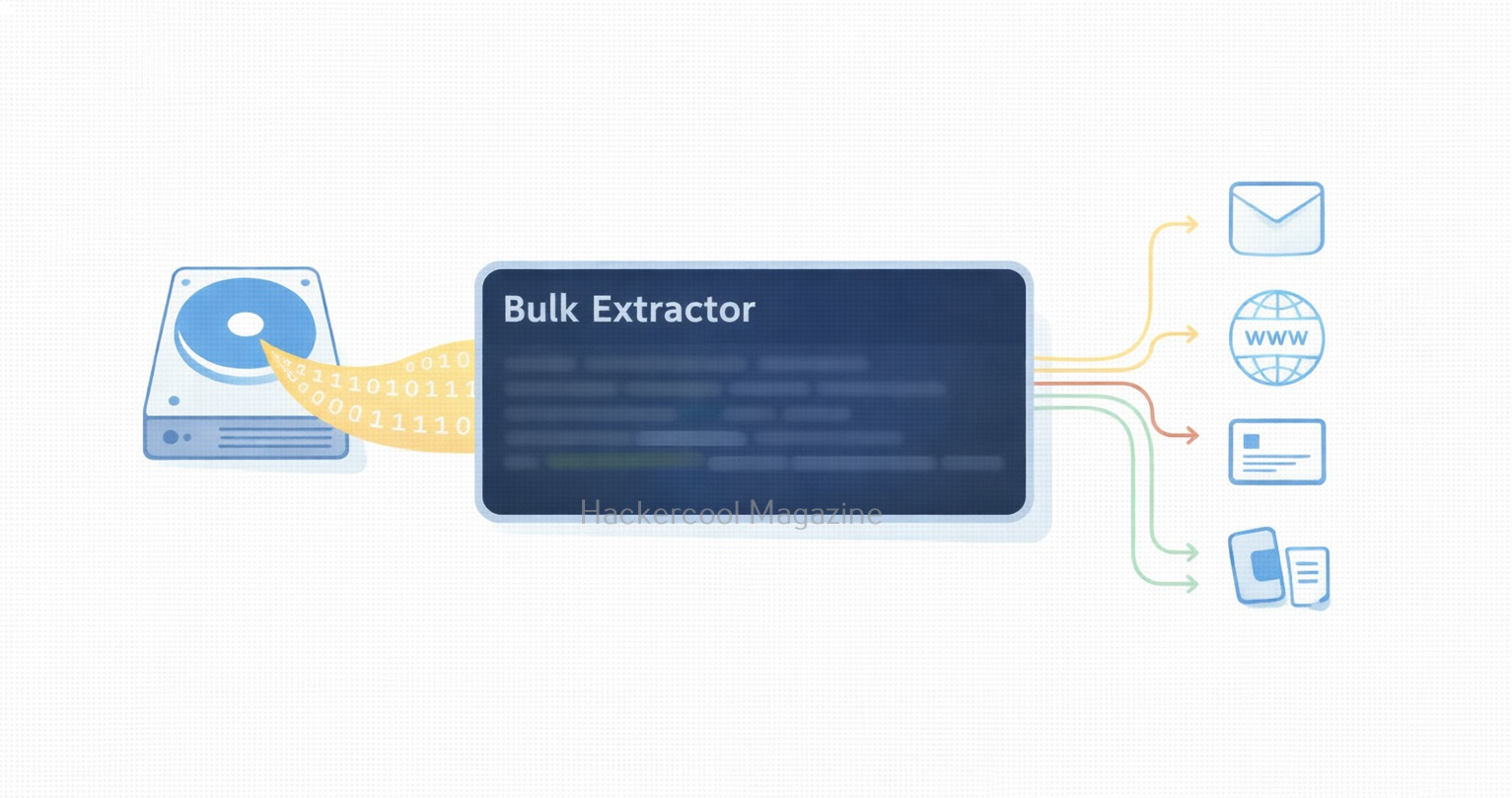
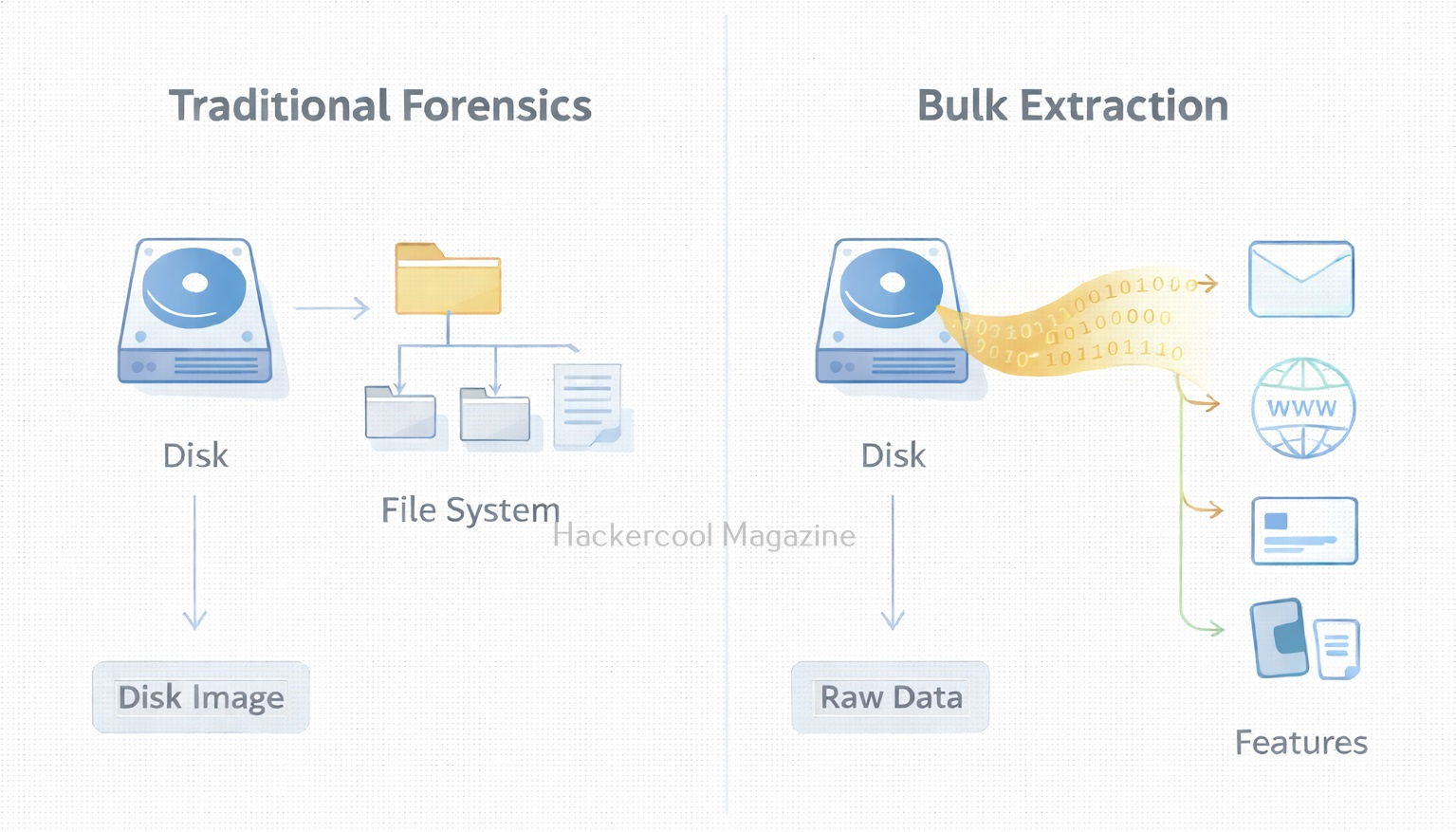
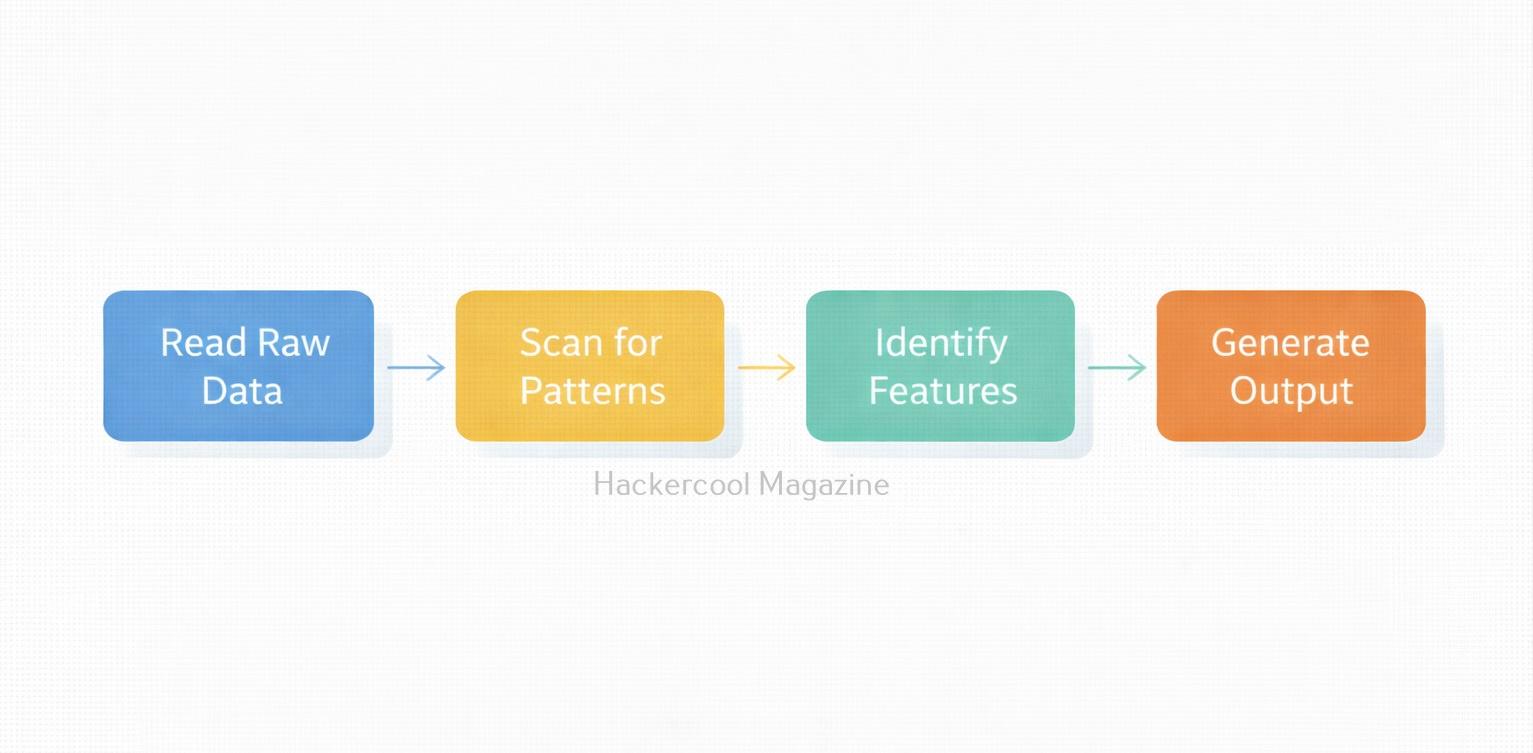
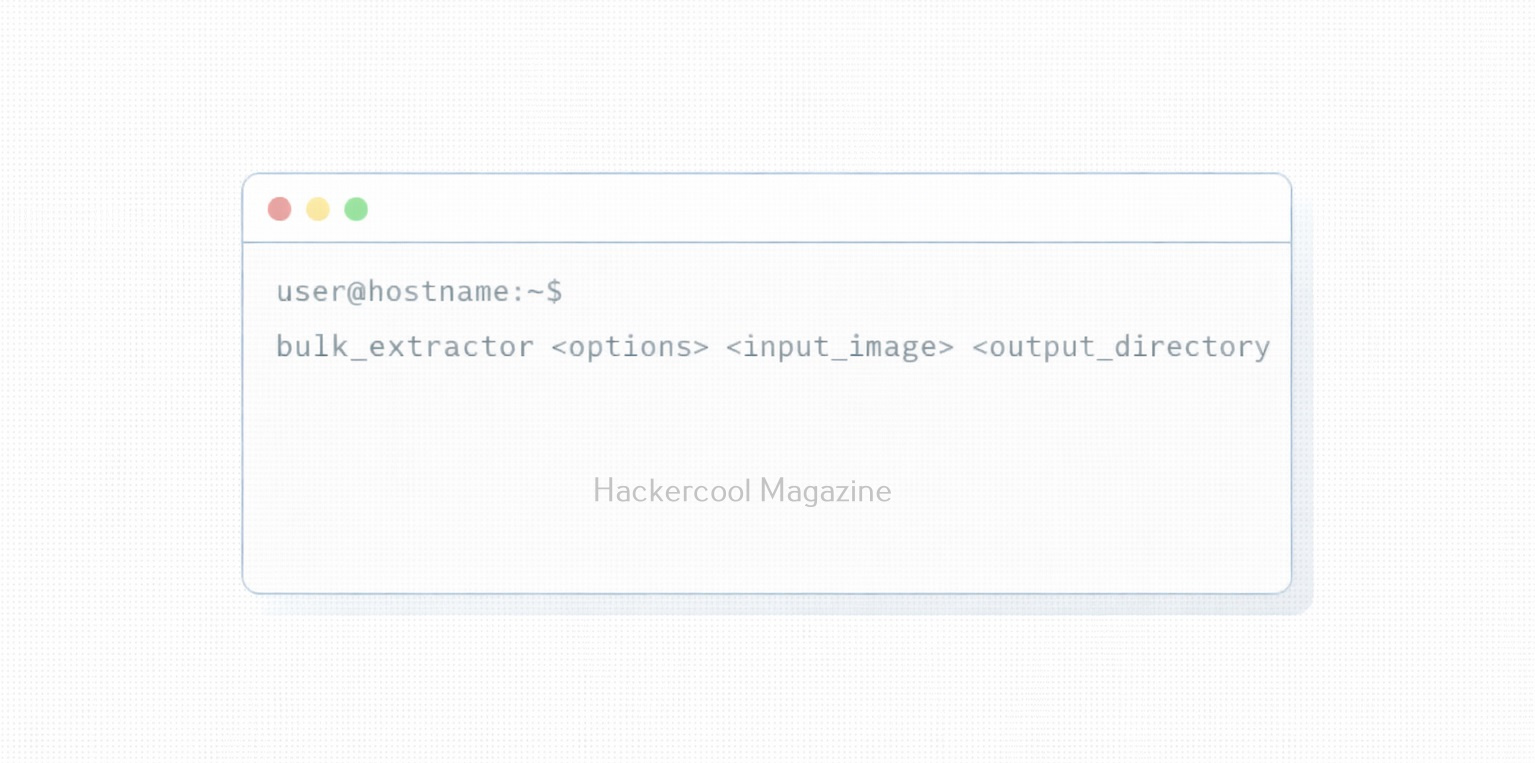
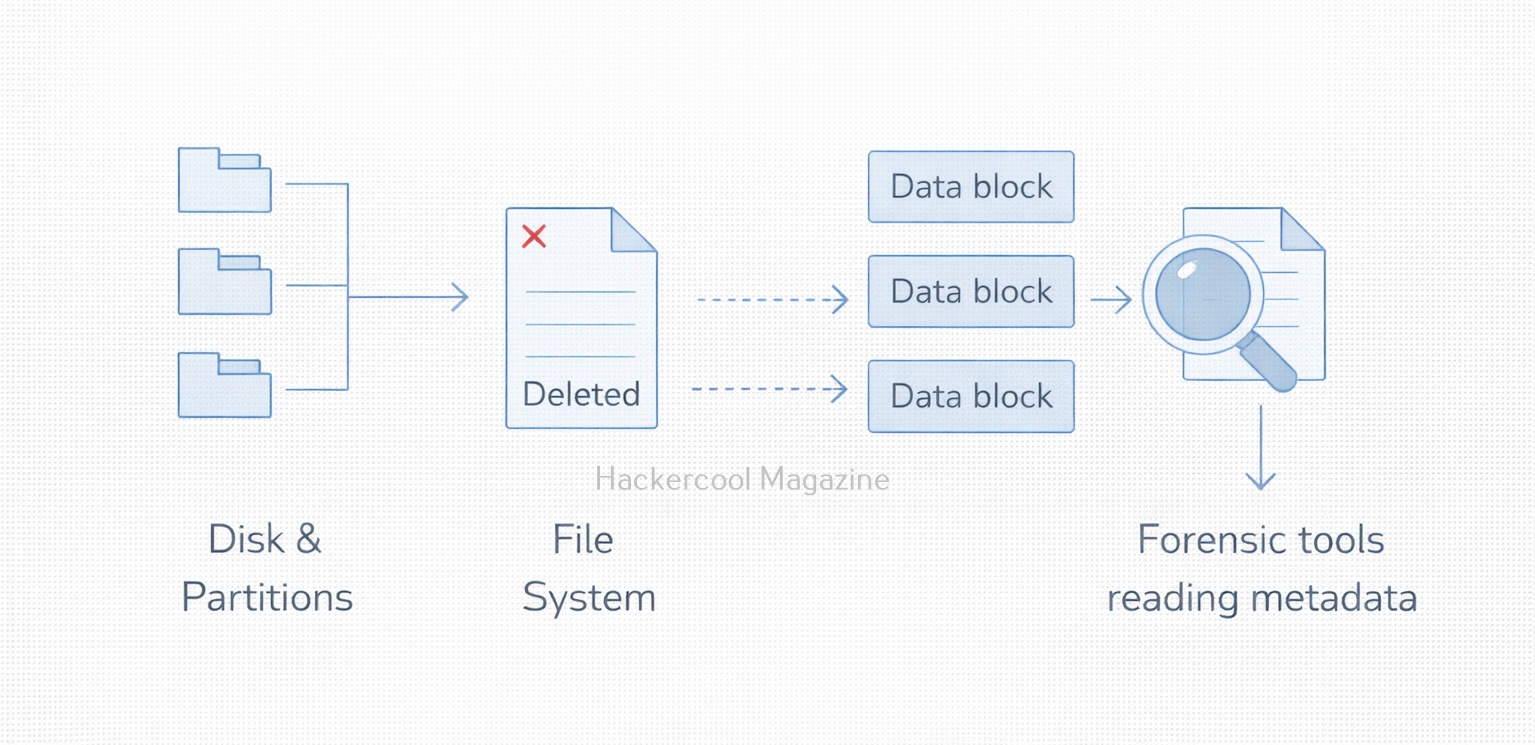
Hello, aspiring Cyber Forensic Investigators. In this article, you will learn about Foremost, a Forensic tool used for file carving. In digital forensics, one of the most common tasks is retrieving deleted or hidden files from storage media. Whether investigators are analyzing a compromised server, a suspect’s hard drive or a damaged USB stick, they often rely on file carving techniques to recover valuable evidence. Among the many tools available, Foremost stands out as a powerful yet simple utility designed for efficient file recovery.
New to Ethical Hacking?
Start your journey with The Beginner Ethical Hacker Starter Kit (2026 Edition).
Inside the free guide, you’ll learn:.
- Ethical hacking fundamentals
- Beginner cybersecurity roadmap
- Essential hacking tools
- Common vulnerabilities explained
Originally developed by the U.S. Air Force Office of Special Investigations (AFOSI) and the Center for Information Systems Security Studies and Research (CISR), Foremost has evolved into one of the most widely used open-source forensic tools for beginners and professionals alike.
This blogpost will walk you through what Foremost is, why it’s so useful and how to start using it even if you’re brand new to digital forensics.

What is Foremost?
Foremost is a file carving tool which means it recovers files based on known file headers and footers rather than file system metadata. This makes it extremely effective when:
- The file system is corrupted
- The partition table is missing
- Files have been deleted
- Metadata like filenames or timestamps no longer exist
Foremost searches raw disk images or partitions and extracts files such as:
- Images (JPG, PNG, GIF, BMP)
- Documents (PDF, DOC, PPT)
- Videos (AVI, MP4)
- Archives (ZIP, RAR)
- Email files and many more, depending on your configuration
Because Foremost works at the byte level, it is fast, reliable and widely used in forensic investigations and CTF-style challenges.
Installing Foremost
Ubuntu / Debian:
On most Linux systems, Foremost is available in built-in repositories. To install this tool on Ubuntu / Debian, we should use commands shown below.
sudo apt-get update
sudo apt-get install foremost
Fedora:
We can install foremost on Fedora using commands shown below.
sudo dnf install foremost
Kali Linux:
Foremost comes preinstalled on Kali Linux.

How Foremost Works?
Foremost works by scanning for known file signatures using a configuration file (/etc/foremost.conf). This file lists the header and footer patterns for each supported file type. For example, JPEGs are identified by following header and footer.
Want to Learn Ethical Hacking Step-by-Step?
If you’re serious about learning cybersecurity, a structured roadmap makes the journey much easier.
Download The Beginner Ethical Hacker Starter Kit (2026 Edition) and discover:
✔ The ethical hacking learning path
✔ Beginner-friendly security concepts
✔ Essential tools ethical hackers use
✔ The most common vulnerabilities explained
- Header:
FFD8 - Footer:
FFD9
Foremost scans the entire disk or forensic image file, identifies these patterns and extracts whatever lies between them. This process is fully automated and saves results into organized folders.

Basic Commands for Beginners
Let’s walk through some essential commands you’ll use during your first forensic analysis.

1. Carving all known file types from a disk image:
To carve all known file types from a disk image, we should use the command shown below.
foremost -i disk-image.dd -o output_folder
Explanation:
In the above command,
-ispecifies the input image-ospecifies where results will be stored
Foremost will automatically create subdirectories for each recovered file type.

2. Recovering only specific file types:
You can also recover specific file types using this tool. Let’s say you want to extract only JPEG images, the command is given below.
foremost -i disk-image.dd -o output -t jpg
You can even specify multiple types of images using command shown below.
foremost -i disk-image.dd -o output -t jpg,png,pdf
This is extremely useful when you’re looking for specific evidence, such as illegal images or stolen PDF documents.
3. Saving a detailed audit log:
Foremost automatically generates an “audit.txt” file in your output folder. To view the audit log, we can use command shown below.
cat output/audit.txt
This log contains:
- Detected file signatures
- Number of files recovered
- Carving start and stop time
- Any errors encountered
This is crucial for forensic report writing.

4. Using a Custom configuration file:
You can modify or create a custom config file to carve rare file types. For example,
foremost -i disk-image.dd -o output -c myconfig.conf
This option is helpful when working with proprietary file formats or adding new signature patterns.
5. Carving files from a raw device (Drive/USB):
We can also carve files from a raw device.
sudo foremost -i /dev/sdb -o usb_recovery
Important:
Never run carving directly on a suspect’s original device. Always work on a forensic image. This command is mainly used for testing or training environments.
When Should You Use Foremost?
Foremost is ideal for:
✔ Recovering deleted files
✔ Extracting evidence from corrupted partitions
✔ File carving during memory forensics (with image dumps)
✔ CTF competitions and capture-the-flag challenges
✔ Beginner-level forensic labs and training
If you’re working with a damaged or heavily modified file system, Foremost is often faster and easier than more complex forensic suites.
Limitations of Foremost
While powerful, Foremost has a few limitations. They are:
- It cannot recover filenames or folder paths
- It may produce false positives for file signatures
- It doesn’t reconstruct fragmented files well
- It cannot analyze metadata
For advanced analysis, we can pair Foremost with The Sleuth Kit, Autopsy or Volatility.
Conclusion
Foremost is one of the best tools for beginners stepping into the world of digital forensics. Its simple command-line interface, speed and ability to recover a wide range of deleted files make it a go-to utility for investigators, students and hobbyists. With just a few commands, you can start carving files from disk images and uncover hidden or deleted data that may hold crucial evidence. If you’re starting your journey into forensic investigations, Foremost is an essential tool to master. Next, learn about Bulk Extractor.

Start Your Ethical Hacking Journey Today
Learning cybersecurity can feel overwhelming at first. The best way to start is with a clear roadmap and the right resources.
Download The Beginner Ethical Hacker Starter Kit (2026 Edition) and get instant access to:
✔ Ethical hacking fundamentals
✔ A beginner cybersecurity learning roadmap
✔ Essential hacking tools every beginner should know
✔ Common vulnerabilities explained simply